Добавлю примеры корреляции в ближайшем обновлении. Самый простой способ расчета корреляции через .ror.plot() основывается на всей доступной статистике. Данных внутри дня там нет. Только месячные данные (adjusted close). Вы можете считать скользящую корреляцию на любых промежутках задавая размер окна в месяцах ror.rolling(window=24).plot()
Визуализацию можно использовать любую. Я показываю на matplotlib, но можно спокойно использовать Seaborn… Это дело вкуса.
Оптимизация с ограничениями (constrained optimization) в okama тоже есть. Можно задавать ограничения на любые веса. Но пока не успел сделать описание этого в ноутбуке. Сами мы активно это используем в процессе создания портфелей.
Что касается полной доходности по ценным бумагам, то она по умолчанию такая, т.к. вместо обычных цен закрытия мы используем adjusted close (учитывает в цене дивидендный доход с учетом реинвестирования). Как раз сейчас немного не хватает ценовой доходности портфеля или актива без учета дивидендов. В планах ввести такие метрики.
Прогнозы делаются сейчас либо по историческим данным либо по свойствам распределения случайной величины. Это основные подходы, рекомендованные в частности CFA. Возможно, в будущем появится и что-то еще. Но главное сейчас, это реализовать общепринятую математику, которая применяется повсеместно.
Safe Withdrawal / Perpetual Withdrawal rates - действительно полезные метрики. Вообще для нас PortfolioVizualizer один из основных “источников вдохновения”
В первую очередь мы планируем сделать прогнозирование wealth index с учетом регулярных пополнений.
Большое спасибо за ваши идеи, вопросы и рекомендации!
Из-за этого, CAGR с реинвестированием приходилось считать самому. Оно, как мне казалось, и понятно, так как доходность с реинвестированием зависит от таймфрейма и должна пересчитываться на каждый заданный период. Может быть, я не до конца разобрался.
Если в okama это уже реализовано, то здорово. Главное, чтобы не оказалось так, что, например, по российским бумагам доходность полная, а по американским ценовая или наоборот. Это может на неверные выводы навести в некоторых случаях.
Adjusted close price - по определению предполагает реинвестирование дивидендов. Причем, если данные дневные, то цена реинвестирования принимается равной цене закрытия. Это некоторое допущение. Но такова модель. Кроме того, в этой модели есть реально неприятные изъяны на уровне математики. Но что делать … adjusted close - это мировой стандарт. Приходится с ним работать, несмотря на все неточности. Есть конечно, вариант, пересчитывать всё самому, но это очень глобальная работа. Мы до такого еще не скоро созреем.
Здесь есть неплохая дискуссия на эту тему:
Сергей, по-моему, это не должно быть большой проблемой - Yahoo Finance (в т.ч. питоновская библиотека уfinance и всевозможные API) выдают Close и Adj Close. Первое - это как раз чисто ценовой индекс с учетом только сплитов. API Мосбиржи, насколько я знаю, выдает ценовые показатели по отдельным бумагам. Дивиденды отдельным запросом.
Но вообще интересно, под какую идею Вам чисто ценовая доходность нужна?
В ценах же ещё и байбэки сидят, а это те же дивиденды по сути - их тоже вычищать придется.
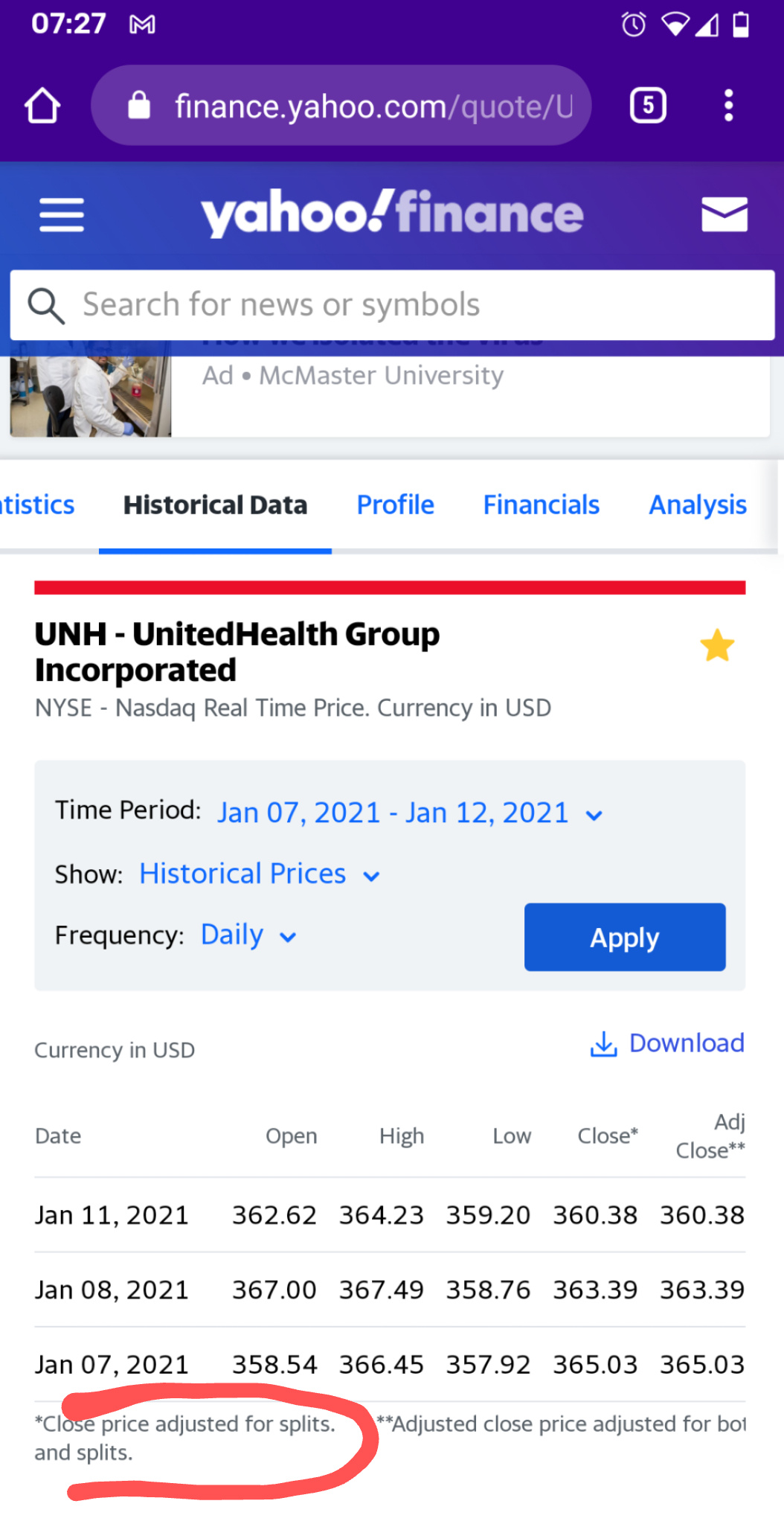
Close - это без учета чего бы то ни было. Сплитов там нет. Просто цены закрытия. А вот в adjusted close как у Yahoo Finance, так и у всех остальных учтены все сплиты и дивиденды.
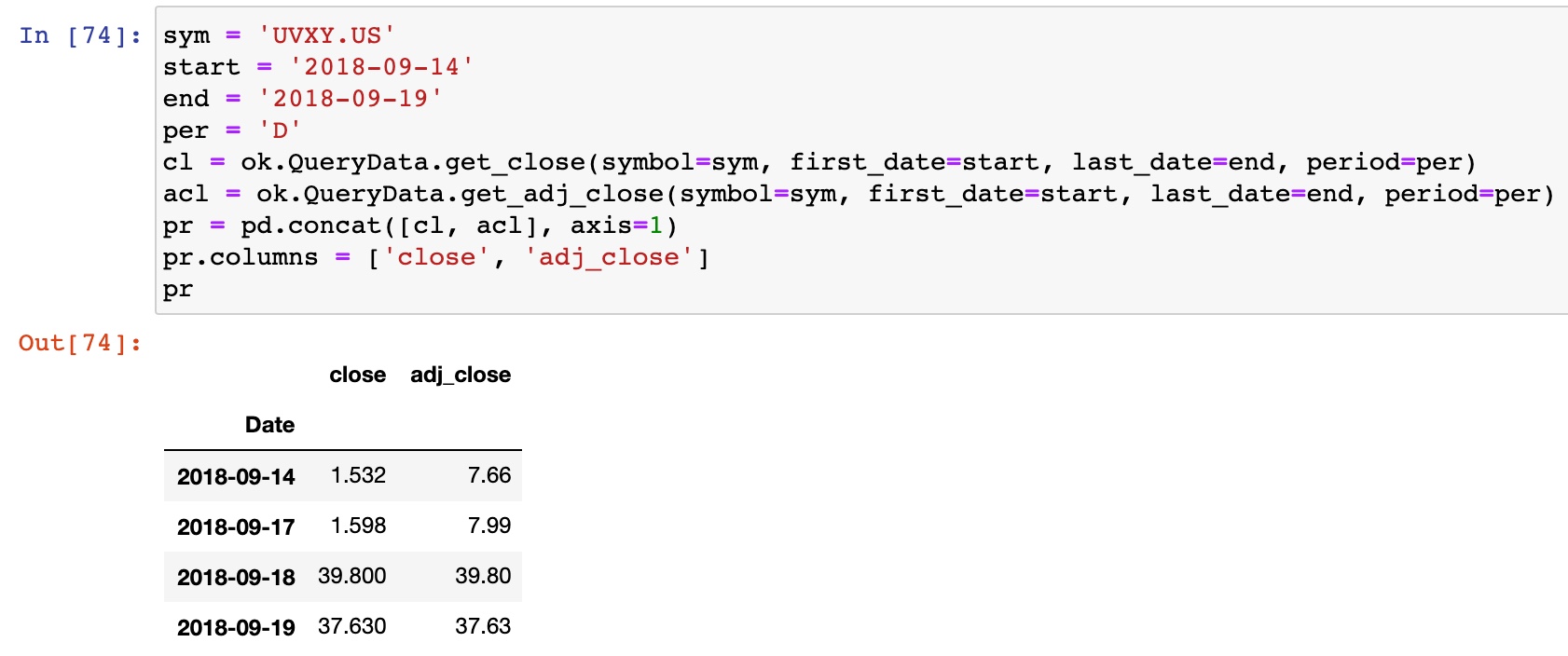
Проблем с получением цен закрытия нет. В базе данных okama они уже присутствуют. Они даже доступны через ok.QueryData.get_close().
В ближайших планах сделать временной ряд цен закрытия атрибутом актива. Нужно это много где. Например, при расчете дивидендной доходности используется не adjusted close а именно цены закрытия. Для понимания, какая часть доходности получена за счет дивидендов на длинных промежутках времени нужны оба показателя. История изменения цены на бумагу сама по себе полезная характеристика.
На сколько я знаю, официально Yahoo Fainance API сейчас не поддерживается. Но раньше они предоставляли цены закрытия без всяких поправок на сплиты. То, что они отображают на графиках не обязательно должно быть одинаковым с данными API.
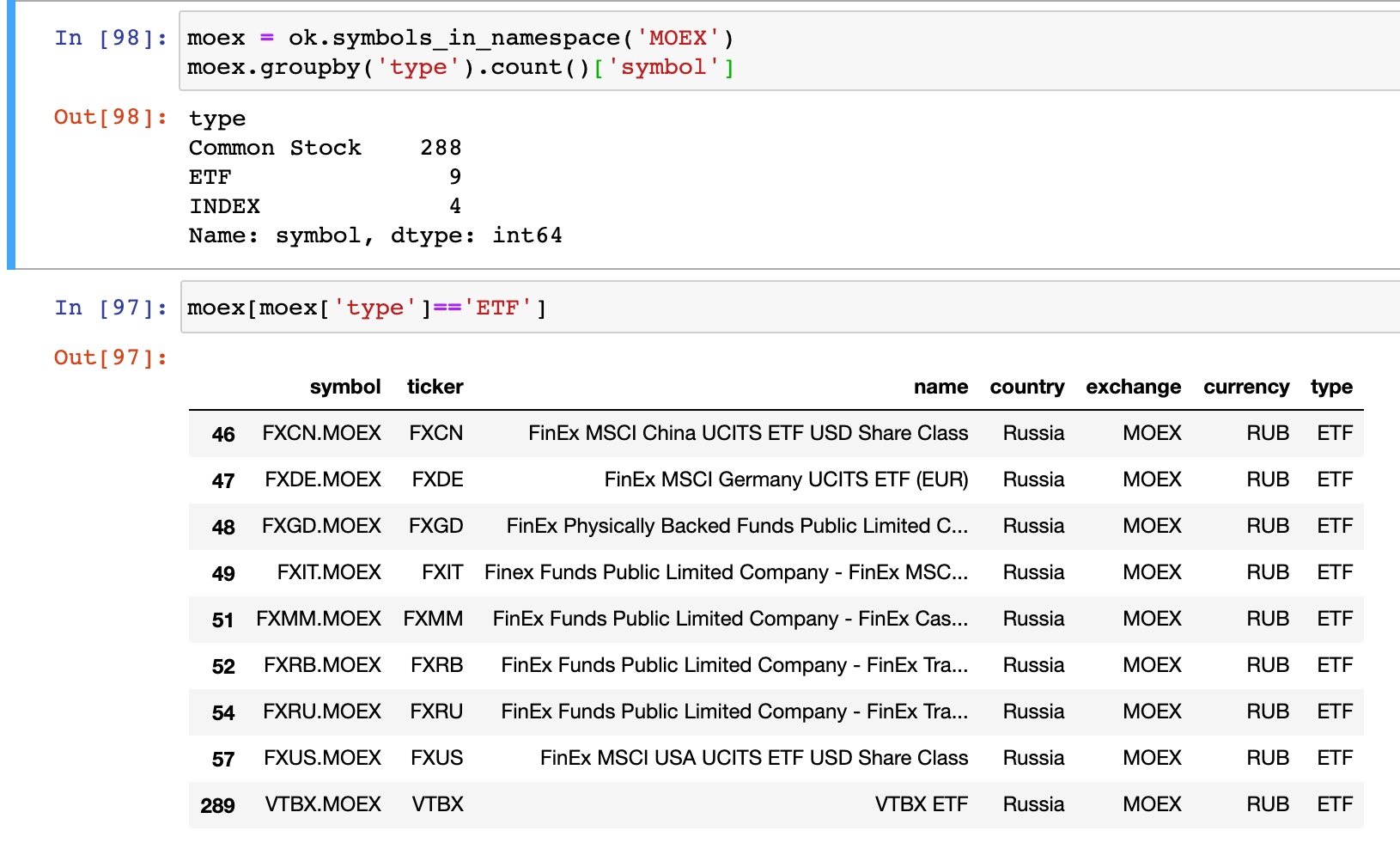
Namespace PIF:
Всего 438 фондов. Я поначалу думал, что это только открытые, интервальные и биржевые, но в базе есть и ряд закрытых фондов. А некоторых фондов, которые активно торгуются на бирже, почему-то нет, например, ФПР Восток-Запад (( Есть ли планы добавить в базу все фонды, которые котируются на ММВБ?
Подскажите как праивльнее получить в okama доходность инструмента за произвольный период, например за последние 6 месяцев? Возможно даже уже есть такой функционал и я его просто не нашёл.
Я пока это так делаю, но есть ощущение что должен быть способ проще:
ls = ['FXGD.MOEX','VTBX.MOEX','VTBE.MOEX','SBGB.MOEX','RUSB.MOEX','FXTB.MOEX','FXDE.MOEX','FXCN.MOEX','FXUS.MOEX']
data = [ok.QueryData.get_close(ticker,first_date=first_date, last_date=last_date, period='M') for ticker in ls]
open_end = [(d[0], d[d.count()-1]) for d in data]
profits = [(t[1]-t[0])/t[0] for t in open_end]
Было бы здорово если бы алгоритм ребалансировки портфеля был завёрнут в какой-нибудь абстрактный патерн типа Strategy/Policy, что бы его можно было переопределять и экспериментировать с разными подходами к ребалансировке.
В классе ‘AssetList’ есть метод .get_cagr(period=None). Он считает полную среднегодовую доходность на произвольных периодах. Возможные значения для period: “YDT” (доходность c начала года), “none” (за весь период) или любое натуральное число (количество лет).
CAGR (Compound Annual Growth Return) - не считается на периодах меньше года, поэтому значения периода меньше года не допускаются.
Кроме того, есть метод .describe([1, 5, 10]), где считаются среднегодовые доходности сразу за произвольное количество периодов одновременно (по умолчанию 1, 5 и 10 лет) и за весь срок.
В на GitHub уже доступна к скачиванию версия с атрибутом .cumulative_return, который считает накопленную (не приведенную к году) доходность за весь срок. Если нужно именно за последние 6 месяцев, то можно отрегулировать срок для AssetList при помощи first_date и last_date, а дальше применить .cumulative_return.
П.С. в вашем примере вы посчитали только ценовую доходность, т.к. close не учитывает полученные дивиденды.
Было бы здорово если бы алгоритм ребалансировки портфеля был завёрнут в какой-нибудь абстрактный патерн типа Strategy/Policy
В планах внедрить параметр rebalancing_period в классе Portfolio для изучения свойств портфеля при разных периодах ребалансировки.
Сейчас есть метод .get_rebalanced_portfolio_return_ts, который позволяет получить временной ряд месячных доходностей для портфеля с годовой ребалансировкой (period=‘year’) или без ребалансировки вообще (period=‘none’). Из этого временного ряда довольно просто получить другие параметры доходности и риска для таких портфелей. Кроме того, .describe() для портфелей показывает сразу среднегодовые доходности на всех периодах для портфелей с ежегодной ребалансировкой, т.к. это наиболее популярный период.
Почему большая часть функций в библиотеке работает только с месячными данными (helpers.py)? В принципе текущий код может быть легко адаптирован для данных с любой частотой, а для ряда функций даже менять ничего не надо…
Основная цель библиотека - работа в рамках Современной теории портфеля с долгосрочными инвестициями. Для этого нужны прогнозы и анализ данных глубиной в годы. Месячных данных данных для этого обычно достаточно. Результат как по доходности, так и по всем метрикам риска обычно приводится к годовым значениям. В дневных данных есть смысл, только если не хватает глубины истории по месячным. Внутри дня данные просто не нужны.
С дневными данными есть технические сложности … Библиотека работает с наборами ценных бумаг, которые торгуются на разных биржах мира. Все фондовые рынки работают по своим расписаниям. Для одних бирж первое января является рабочим днем, для других нет. Работать с такими наборами, где выпадают дни, сложно. Можно конечно, просто убирать дни, когда где-то нет торгов. Но тогда будет выпадать много информации. Можно использовать цены закрытия предыдущих дней, когда торги были. Но это будет искажать данные по риску. В общем, необходимо решать такого рода сложности. А полезность при этом под большим вопросом.