Я занимаюсь автоматизацией тестированя и сейчас изучаю pytest,
Хотел бы вам помочь с тестами, ну и преобрести опыт в pytest.
Что для вас сейчас самое актуальное, новые тесты или исправление существующих?
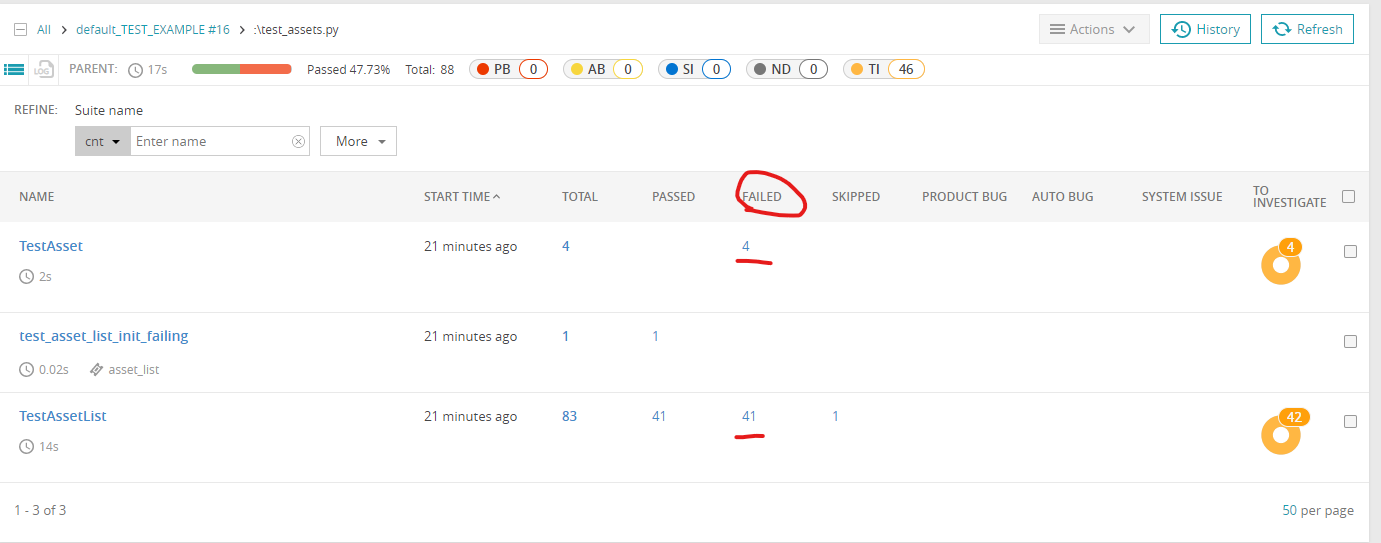
Запустил ваши тести из папки /test, вот результаты:
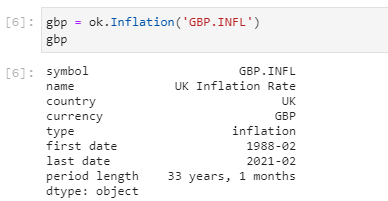
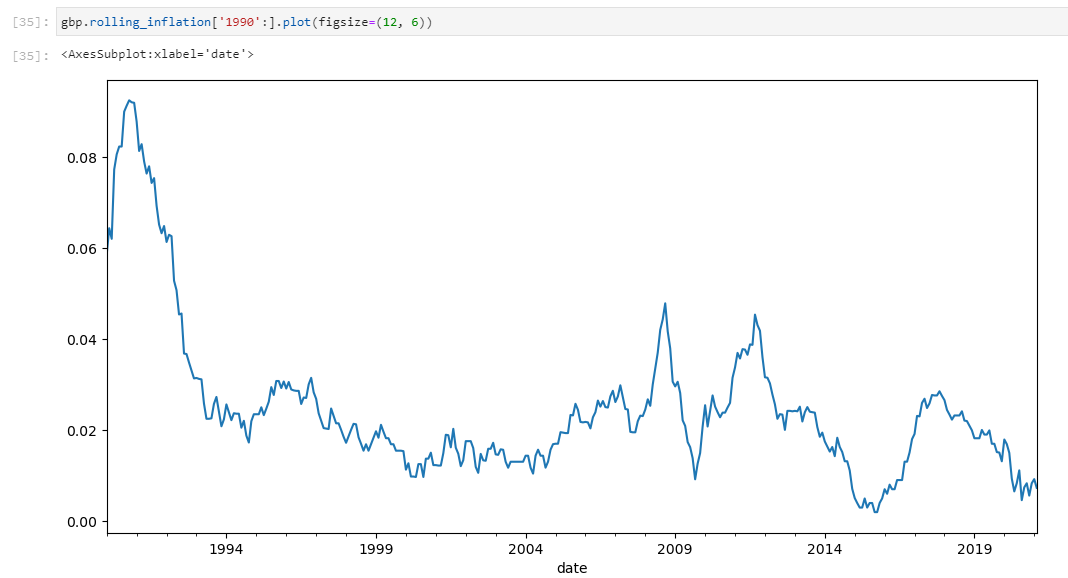
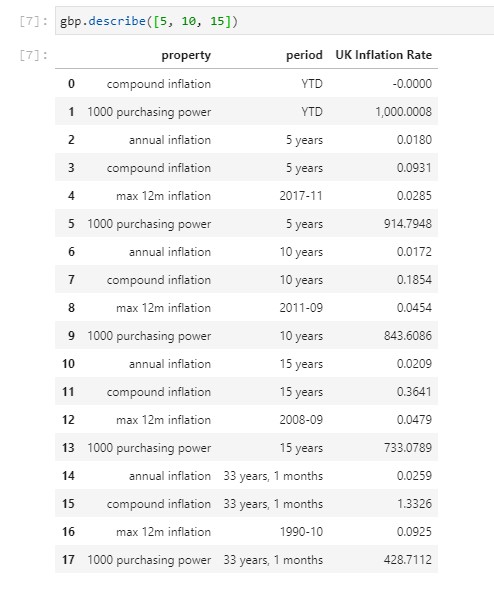
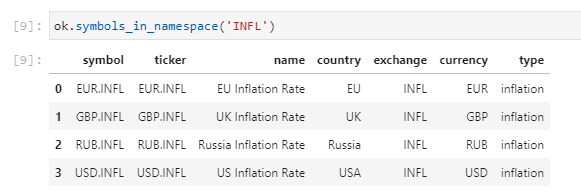
Сергей, добрый день. Подскажите, пожалуйста, есть ли готовый метод получения среднегодовой инфляции? Месячную догадался вытянуть через inflation_ts, годовую не нашел.
Для работы с инфляцией есть отдельный класс Inflation.
Например, для вычисления инфляции британского фунта:
Пока нет документации, можно просто руководствоваться списком методов:
Добрый вечер. Посыл создания такой библиотеки интересный, но бесполезный. Причина банальна - прошлые результаты ничего не гарантируют. А в вашем случае вы вообще игнорируете сам бизнес - то есть фундаментал. Вы рассматриваете только массив отвлеченных от сути бизнеса цифр (цен) и неважно какая компания стоит за ними - AAPL, SPY или BTC… А имея фундаментальные данные, можно уже рассчитывать метрики, строить прогнозные модели… и смотреть вперед, а не только назад. Лично я сейчас работаю над парсингом базы отчетов SEC EDGAR формата XBRL - собираю исторические данные для последующей работы с ними. Так же работаю над парсерами других сайтов для получения нужных данных, к примеру можно собрать состав ETF и анализировать не его цену, а его составляющие бизнесы.
Проект создан для тех, кто понимает что такое Современная теория портфеля и как ей пользователя. Если вы этого не понимаете, вряд ли вам здесь будет интересно …
MPT - это чистая математика и составляет менее 1% от всей проблемы составления качественного портфеля. Основной функционал МРТ (около 97%) реализовывается за пару часов с помощью стандартных фреймворков. Остальные 3% от МРТ - это создание всяких необязательных количественных метрик, уточняющих и корректирующих результаты МРТ.
А вот каким образом вы решаете самую главную 99%-ную проблему - подбор качественных бумаг в портфель - с помощью дротика мартышки? А там, на минуточку, десятки тысяч бумаг со всего мира!
Честно говоря, мне жалко того работодателя, который готов платить зарплату человеку, вводящему его в заблуждение и пытающемуся за его счет изобрести велосипед (portfoliovisualizer.com), как бы “решая” те оставшиеся 3% задач из МРТ.
Если вы хотя бы поверхностно знакомы с MPT, до сами должны знать ответы на ваши вопросы. MPT никогда не создавалась для выбора активов. Дискуссия о целесообразности применения MPT здесь неуместна.
Еще раз повторяю, если не интересен проект, не надо здесь писать. После еще одного подобного поста будет бан.
Добрый день Сергей, не могли бы Вы добавить в метод search дополнительный параметр что бы указывать неймспейс в котором нужно произвести поиск? Например написать что-то в духе ok.search(“MSCI”, “INDX”) что бы найти все индексы у которых в названии встречается MSCI?
Приветствую …
Согласен. Хорошее предложение. Тем более что база данных тикеров скоро будет включать гораздо больше полей. Например, появится, название бенчмарка, тип базового актива, комиссия для ETF.
Возможно тогда стоит просто предоставить интерфейс к БД как к итерируемому контейнеру с объектами описывающими тикер, что бы с ней можно было работать стандартными средствами питона, например, делать выборки теми же генераторами?
Как-нибудь в таком духе:
bd = ok.BD.Load()
filtered_list = (x
for x in bd
if x.description.lower().find("msci")>=0 and x.namespace=="INDX")
тогда уже и регулярочку можно будет где-то жахнуть при желании и сделать подвыборки из выборок т.п.